diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..a53d962
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1 @@
+*.mp4
\ No newline at end of file
diff --git a/doc/音频检测/READMENEW.md b/doc/音频检测/READMENEW.md
new file mode 100644
index 0000000..9d172bb
--- /dev/null
+++ b/doc/音频检测/READMENEW.md
@@ -0,0 +1,120 @@
+# **音频模型训练:声音分类器** 👂🎤
+
+你好!欢迎来到这篇音频模型训练教程。在本教程中,我将手把手带你创建一个机器学习模型,用来识别不同的声音。你可以将其应用于任何需要区分特定声音的场景。
+
+## 如何训练模型:从零开始构建你的分类器
+
+### **步骤1:了解声音分类模型**
+
+在开始训练之前,我们需要了解声音分类模型的基本原理。模型的工作原理类似于人类学习识别声音:当听到一种声音时,我们会记住它的特征,并在下次听到类似声音时进行匹配。
+
+#### **1.1 声音特征提取**
+
+当声音进入麦克风,它会转化为数字信号。我们的AI通过处理这些信号,生成**频谱图**(Spectrogram)。声谱图是声音的视觉表示,它通过颜色和图案展示了声音的音高、响度、持续时间等关键信息。AI通过识别声谱图上的独特模式来区分不同的声音。
+
+#### **1.2 迁移学习与预训练模型**
+
+为了提高训练效率,我们采用**迁移学习**。这意味着我们不会从零开始训练模型,而是利用一个已经在大规模音频数据集上进行过预训练的“听音教授”——**Speech Commands 模型**。
+这个预训练模型已经学会了识别日常声音和口令词,并特别内置了对**“背景噪音” (`_background_noise_`)** 的理解。因此,训练过程的关键在于:
+
+* **识别背景噪音:** 首先让模型学习你所在环境的背景噪音,以便它能区分目标声音和环境杂音。
+* **识别自定义声音:** 在预训练模型的基础上,向它提供你想要识别的特定声音样本,模型将快速学习并区分这些新声音。
+
+#### **1.3 KNN分类**
+
+在提取出声音的特征后,模型使用**K-近邻算法(KNN)**进行分类。它会将当前接收到的声音特征与所有已学习的特征进行比较,找到最相似的匹配项,从而判断当前声音的类别。
+
+### **步骤2:创建项目与收集学习样本**
+
+现在,让我们开始在网站上操作,创建并训练你的声音分类模型。
+
+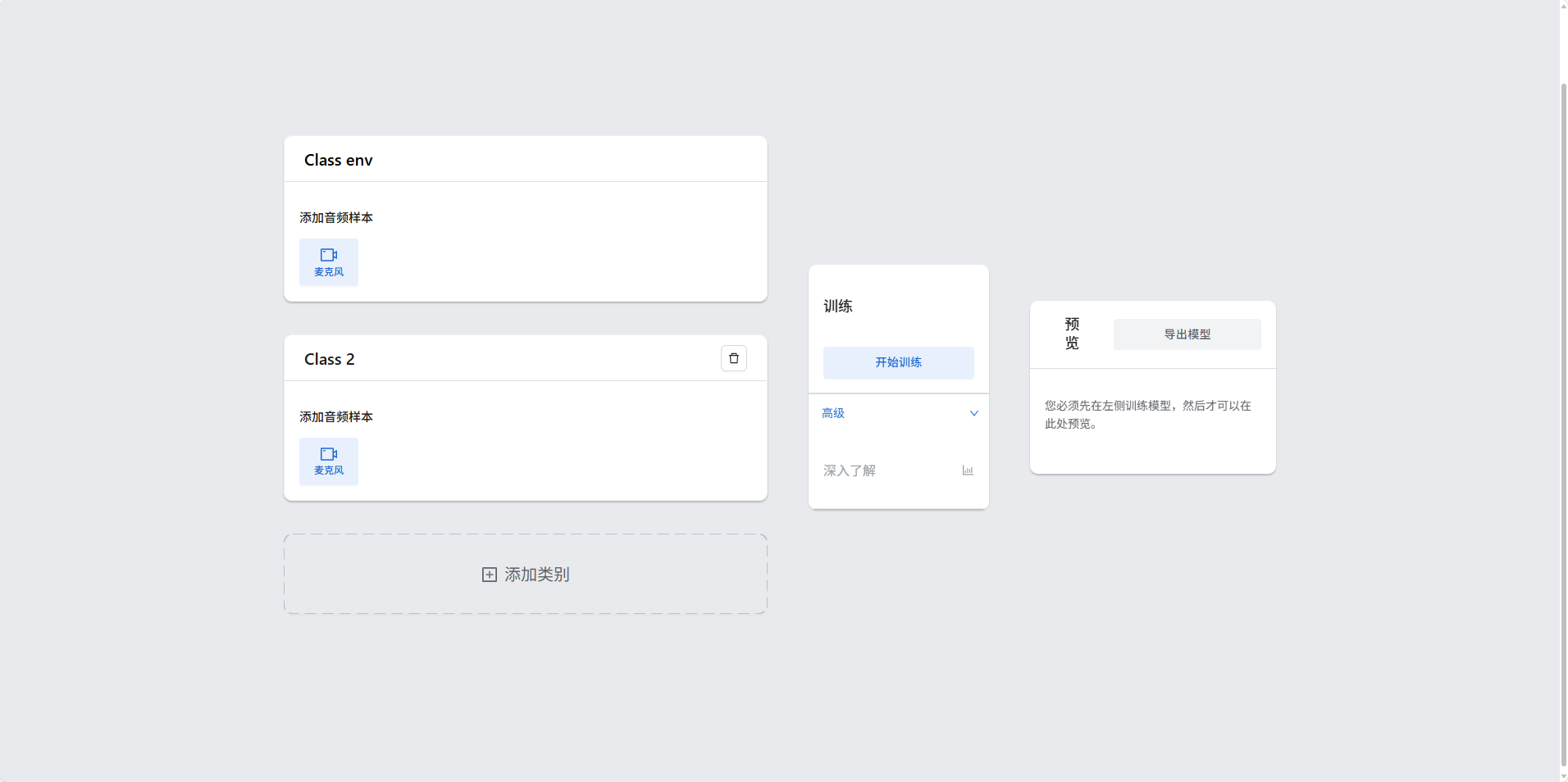 +
+
+在页面上,你会看到几个主要区域:**状态信息**、**背景噪音录制**、**自定义类别管理**、**模型控制**和**预测结果显示**。
+
+#### **2.1 录制背景噪音**
+
+这是非常关键的第一步。为了让模型更好地识别目标声音,它需要先学习你所处环境的“无意义”声音。
+
+* 找到“**🤫 1. 录制背景噪音**”区域。
+* 保持周围环境安静,不要发出你计划训练的特定声音。
+* 点击“**录制样本**”按钮(背景噪音的按钮通常是红色或特别标记的)。
+* 系统会自动为你录制几段背景噪音。你会看到“样本数量”在增加。
+
+
+
+* _小贴士:_ 确保录制时不要发出目标声音。建议录制 5-10 个样本以获得更好的效果。
+
+#### **2.2 录制自定义声音类别样本**
+
+接下来,为模型提供你想要识别的自定义声音样本。
+
+* **添加新类别:** 在“**🗣️ 2. 录制您要分类的声音**”下方的输入框中,输入你想要识别的声音的名称(例如“拍手”、“吹口哨”、“开始”、“停止”)。然后点击“**添加类别**”按钮。
+* 一个新的类别块将会出现,其中包含“样本数量”和“录制样本”按钮。
+* **为每个类别录制样本:**
+ * 选择一个你刚创建的类别。
+ * 每次点击“**录制样本**”按钮,发出该类别的声音一次。例如,如果你创建了“拍手”类别,就对着麦克风拍一次手。
+ * 系统会自动帮你录制多段样本。你会看到对应类别的“样本数量”在增加。
+
+
+* _小贴士:_ 尝试从不同强度、不同方式发出同一个声音,让模型学习到更丰富的特征。每个类别至少录制 5-10 个样本效果最好。
+* 重复以上步骤,添加并录制所有你想要识别的声音类别。
+
+### **步骤3:训练模型**
+
+当所有类别的样本(包括背景噪音)都准备好后,即可开始模型训练。
+
+* 点击“**🚀 3. 训练模型**”按钮。
+* “状态”区域将显示模型的训练进度(例如“训练 Epoch 1/50”)。此过程可能需要一些时间,具体取决于样本数量和网络速度。
+
+
+
+* 请耐心等待。当“状态”显示“模型训练完成!”时,表示模型已完成训练。
+
+### **步骤4:开始识别并测试模型**
+
+训练完成后,你可以立即测试模型的效果。
+
+* 点击“**👂 4. 开始识别**”按钮。
+* 对着麦克风发出你训练过的声音,或者保持安静(让它识别背景噪音)。
+* 模型会即时显示识别结果,包括识别到的声音类别和置信度(例如:“预测结果:拍手 (置信度: 98%)”)。
+
+
+* 测试完成后,点击“**⏸️ 停止识别**”按钮暂停识别。
+
+## 值得尝试的事:探索模型的局限性
+
+现在模型可以工作了,你可以测试它的效果——更有趣的是,去**找到它无法正常工作的边界**。尝试找到机器学习的极限所在!
+
+**思考一下:** 对于计算机来说,声音只是一堆数字信号的排列组合。所以,你并没有真正教会计算机什么是“拍手”,你只是教会了它:这个特定频率、特定时长的声音(在某个背景下)被标记为“拍手”——对计算机来说,它看到的仅仅是声谱图的像素而已。
+
+### **案例1:模型识别错误怎么办?**
+
+* 如果模型判断错误,这可能意味着采集的样本不足、不够清晰或不够多样化。
+* **尝试:** 重新选择判断错误的类别,补充更多样本,特别是那些与易混淆声音相似的样本。
+
+### **案例2:样本数量对模型性能的影响**
+
+* **思考题:** 如果我只为每个声音类别采集一个样本,模型能学会吗?(答案:通常很难。模型需要多样的样本来学习其泛化能力。)
+* **你可以尝试:** 分别使用少量(例如每个类别 3-5 个)和大量(例如每个类别 20-30 个)样本训练模型,并对比它们的识别准确率。你可能会发现一个有趣的规律。
+
+### **案例3:尝试不同的场景和声音变化**
+
+
+* **测试:** 尝试用不同的口音、语速或距离对着麦克风发出指令,观察模型识别的稳定性。
+* **环境噪声:** 在嘈杂的环境下测试模型,看它是否还能准确区分你的指令。
+* **“欺骗”模型:** 尝试播放一段与你训练的声音相似但并非你训练过的录音,看看模型如何反应。思考如何训练它,使其不会混淆。
+
+## 你能用它做什么?
+
+你可以导出你训练好的模型,用它来做一些有趣的事情!
+
+我制作了一个[实时分类器](https://dev-daily.goood.space/),你可以把自己训练的模型导入来进行实时预测,看看它的实际应用效果!
+
+## 现在做什么?
+
+* **立刻开始创建你自己的声音识别模型吧!** 探索人工智能的奥秘!
+* 或者,你也可以阅读我们的其他教程:
+ * [如何制作图像模型教程]()
+ * [如何制作姿势模型教程]()
\ No newline at end of file
diff --git a/doc/音频检测/音频模型训练界面.png b/doc/音频检测/音频模型训练界面.png
new file mode 100644
index 0000000..efa3d73
Binary files /dev/null and b/doc/音频检测/音频模型训练界面.png differ
diff --git a/game/贪吃蛇/snake_game.html b/game/贪吃蛇/snake_game.html
index 2ac3fce..2068ebe 100644
--- a/game/贪吃蛇/snake_game.html
+++ b/game/贪吃蛇/snake_game.html
@@ -422,11 +422,10 @@
+
+
+在页面上,你会看到几个主要区域:**状态信息**、**背景噪音录制**、**自定义类别管理**、**模型控制**和**预测结果显示**。
+
+#### **2.1 录制背景噪音**
+
+这是非常关键的第一步。为了让模型更好地识别目标声音,它需要先学习你所处环境的“无意义”声音。
+
+* 找到“**🤫 1. 录制背景噪音**”区域。
+* 保持周围环境安静,不要发出你计划训练的特定声音。
+* 点击“**录制样本**”按钮(背景噪音的按钮通常是红色或特别标记的)。
+* 系统会自动为你录制几段背景噪音。你会看到“样本数量”在增加。
+
+
+
+* _小贴士:_ 确保录制时不要发出目标声音。建议录制 5-10 个样本以获得更好的效果。
+
+#### **2.2 录制自定义声音类别样本**
+
+接下来,为模型提供你想要识别的自定义声音样本。
+
+* **添加新类别:** 在“**🗣️ 2. 录制您要分类的声音**”下方的输入框中,输入你想要识别的声音的名称(例如“拍手”、“吹口哨”、“开始”、“停止”)。然后点击“**添加类别**”按钮。
+* 一个新的类别块将会出现,其中包含“样本数量”和“录制样本”按钮。
+* **为每个类别录制样本:**
+ * 选择一个你刚创建的类别。
+ * 每次点击“**录制样本**”按钮,发出该类别的声音一次。例如,如果你创建了“拍手”类别,就对着麦克风拍一次手。
+ * 系统会自动帮你录制多段样本。你会看到对应类别的“样本数量”在增加。
+
+
+* _小贴士:_ 尝试从不同强度、不同方式发出同一个声音,让模型学习到更丰富的特征。每个类别至少录制 5-10 个样本效果最好。
+* 重复以上步骤,添加并录制所有你想要识别的声音类别。
+
+### **步骤3:训练模型**
+
+当所有类别的样本(包括背景噪音)都准备好后,即可开始模型训练。
+
+* 点击“**🚀 3. 训练模型**”按钮。
+* “状态”区域将显示模型的训练进度(例如“训练 Epoch 1/50”)。此过程可能需要一些时间,具体取决于样本数量和网络速度。
+
+
+
+* 请耐心等待。当“状态”显示“模型训练完成!”时,表示模型已完成训练。
+
+### **步骤4:开始识别并测试模型**
+
+训练完成后,你可以立即测试模型的效果。
+
+* 点击“**👂 4. 开始识别**”按钮。
+* 对着麦克风发出你训练过的声音,或者保持安静(让它识别背景噪音)。
+* 模型会即时显示识别结果,包括识别到的声音类别和置信度(例如:“预测结果:拍手 (置信度: 98%)”)。
+
+
+* 测试完成后,点击“**⏸️ 停止识别**”按钮暂停识别。
+
+## 值得尝试的事:探索模型的局限性
+
+现在模型可以工作了,你可以测试它的效果——更有趣的是,去**找到它无法正常工作的边界**。尝试找到机器学习的极限所在!
+
+**思考一下:** 对于计算机来说,声音只是一堆数字信号的排列组合。所以,你并没有真正教会计算机什么是“拍手”,你只是教会了它:这个特定频率、特定时长的声音(在某个背景下)被标记为“拍手”——对计算机来说,它看到的仅仅是声谱图的像素而已。
+
+### **案例1:模型识别错误怎么办?**
+
+* 如果模型判断错误,这可能意味着采集的样本不足、不够清晰或不够多样化。
+* **尝试:** 重新选择判断错误的类别,补充更多样本,特别是那些与易混淆声音相似的样本。
+
+### **案例2:样本数量对模型性能的影响**
+
+* **思考题:** 如果我只为每个声音类别采集一个样本,模型能学会吗?(答案:通常很难。模型需要多样的样本来学习其泛化能力。)
+* **你可以尝试:** 分别使用少量(例如每个类别 3-5 个)和大量(例如每个类别 20-30 个)样本训练模型,并对比它们的识别准确率。你可能会发现一个有趣的规律。
+
+### **案例3:尝试不同的场景和声音变化**
+
+
+* **测试:** 尝试用不同的口音、语速或距离对着麦克风发出指令,观察模型识别的稳定性。
+* **环境噪声:** 在嘈杂的环境下测试模型,看它是否还能准确区分你的指令。
+* **“欺骗”模型:** 尝试播放一段与你训练的声音相似但并非你训练过的录音,看看模型如何反应。思考如何训练它,使其不会混淆。
+
+## 你能用它做什么?
+
+你可以导出你训练好的模型,用它来做一些有趣的事情!
+
+我制作了一个[实时分类器](https://dev-daily.goood.space/),你可以把自己训练的模型导入来进行实时预测,看看它的实际应用效果!
+
+## 现在做什么?
+
+* **立刻开始创建你自己的声音识别模型吧!** 探索人工智能的奥秘!
+* 或者,你也可以阅读我们的其他教程:
+ * [如何制作图像模型教程]()
+ * [如何制作姿势模型教程]()
\ No newline at end of file
diff --git a/doc/音频检测/音频模型训练界面.png b/doc/音频检测/音频模型训练界面.png
new file mode 100644
index 0000000..efa3d73
Binary files /dev/null and b/doc/音频检测/音频模型训练界面.png differ
diff --git a/game/贪吃蛇/snake_game.html b/game/贪吃蛇/snake_game.html
index 2ac3fce..2068ebe 100644
--- a/game/贪吃蛇/snake_game.html
+++ b/game/贪吃蛇/snake_game.html
@@ -422,11 +422,10 @@
姿态控制说明
- - 向上: 双手举过头顶 (分类0)
- - 向下: 双手放在身体两侧或下垂 (分类1)
- - 向左: 左手平举 (分类2)
- - 向右: 右手平举 (分类3)
- - 静止: 无特定动作 (游戏开始前/结束后姿态)
+ - 向上: 双手举过头顶 (class1)
+ - 向下: 双手两侧下垂 (class2)
+ - 向左: 左手平举 (class3)
+ - 向右: 右手平举 (class4)
(确保在摄像头画面中能清晰识别全身)
@@ -565,31 +564,31 @@
- // 自动加载模型
- const cdnModelJsonUrl = 'https://goood-space-assets.oss-cn-beijing.aliyuncs.com/public/models/pose-knn-model.json';
+ // // 自动加载模型
+ // const cdnModelJsonUrl = 'https://goood-space-assets.oss-cn-beijing.aliyuncs.com/public/models/pose-knn-model.json';
- try {
- await loadKNNModelData(null, cdnModelJsonUrl); // 传入 CDN URL, file 为 null
- statusDisplay.textContent = 'CDN 姿态识别模型加载成功!可以开始游戏了。';
- isModelLoaded = true; // 标记模型已加载
- startBtn.disabled = false; // 启用开始游戏按钮
- updateGameStatus('ready'); // 更新游戏状态
- } catch (cdnError) {
- console.warn('CDN KNN 模型数据自动加载失败:', cdnError);
- statusDisplay.textContent = `CDN 模型加载失败: ${cdnError.message}。请手动导入模型。`;
- isModelLoaded = false; // 标记模型未加载
- startBtn.disabled = true; // 模型未加载,开始按钮仍禁用
- importModelBtn.disabled = false; // 允许手动导入
- updateGameStatus('initial'); // 保持初始状态
- }
- // --- 结束 CDN 自动加载 ---
+ // try {
+ // await loadKNNModelData(null, cdnModelJsonUrl); // 传入 CDN URL, file 为 null
+ // statusDisplay.textContent = 'CDN 姿态识别模型加载成功!可以开始游戏了。';
+ // isModelLoaded = true; // 标记模型已加载
+ // startBtn.disabled = false; // 启用开始游戏按钮
+ // updateGameStatus('ready'); // 更新游戏状态
+ // } catch (cdnError) {
+ // console.warn('CDN KNN 模型数据自动加载失败:', cdnError);
+ // statusDisplay.textContent = `CDN 模型加载失败: ${cdnError.message}。请手动导入模型。`;
+ // isModelLoaded = false; // 标记模型未加载
+ // startBtn.disabled = true; // 模型未加载,开始按钮仍禁用
+ // importModelBtn.disabled = false; // 允许手动导入
+ // updateGameStatus('initial'); // 保持初始状态
+ // }
+ // // --- 结束 CDN 自动加载 ---
updateGameUI(); // 确保 UI 在初始化结束时更新一次
} catch (error) {
console.error("应用初始化失败:", error);
statusDisplay.textContent = `初始化失败: ${error.message}`;
- alert(`应用初始化失败: ${error.message}\n请检查摄像头权限、网络连接或刷新页面。`);
+ // alert(`应用初始化失败: ${error.message}\n请检查摄像头权限、网络连接或刷新页面。`);
updateGameStatus('initial');
}
}
@@ -618,7 +617,7 @@
resolve();
}).catch(reject);
};
- setTimeout(() => reject(new Error('摄像头元数据加载或播放超时')), 10000);
+ // setTimeout(() => reject(new Error('摄像头元数据加载或播放超时')), 10000);
});
} catch (error) {
if (error.name === 'NotAllowedError') {
@@ -842,22 +841,22 @@
// 更新页面上的映射显示,如果需要的话。
// 确保 instructions 中的分类名称与 importedClassNames 保持一致
- const instructionListItems = document.querySelectorAll('.instructions li');
- instructionListItems.forEach((item, index) => {
- const classId = String(index); // 假定指令顺序与分类ID一致
- const classNameFromModel = importedClassNames[classId] || '未定义';
- let controlDesc = '';
- switch(classId) {
- case '0': controlDesc = '双手举过头顶'; break;
- case '1': controlDesc = '双手放在身体两侧或下垂'; break;
- case '2': controlDesc = '左手平举'; break;
- case '3': controlDesc = '右手平举'; break;
- default: controlDesc = '未知动作';
- }
- item.querySelector('span').innerHTML = `${controlDesc} (分类${classId}: ${classNameFromModel})`;
- // 如果你的 instructions 区域已经有预设的文字,并且你只希望更新 Classification ID,
- // 可以根据 HTML 结构微调这里的更新逻辑。
- });
+ // const instructionListItems = document.querySelectorAll('.instructions li');
+ // instructionListItems.forEach((item, index) => {
+ // const classId = String(index); // 假定指令顺序与分类ID一致
+ // const classNameFromModel = importedClassNames[classId] || '未定义';
+ // let controlDesc = '';
+ // switch(classId) {
+ // case '0': controlDesc = '双手举过头顶'; break;
+ // case '1': controlDesc = '双手放在身体两侧或下垂'; break;
+ // case '2': controlDesc = '左手平举'; break;
+ // case '3': controlDesc = '右手平举'; break;
+ // default: controlDesc = '未知动作';
+ // }
+ // item.querySelector('span').innerHTML = `${controlDesc} (分类${classId}: ${classNameFromModel})`;
+ // // 如果你的 instructions 区域已经有预设的文字,并且你只希望更新 Classification ID,
+ // // 可以根据 HTML 结构微调这里的更新逻辑。
+ // });
statusDisplay.textContent = '姿态模型导入成功!可以开始游戏了。';